
Monitoring NexJ Model Server with Grafana dashboards
You can monitor the health of your application servers over a defined period of time using Grafana dashboards. Grafana is an open-source metric analytics and visualization suite commonly used for visualizing time series data for infrastructure and application analytics.
Dashboards can be shared with NexJ Support if needed.
Chrome is the recommended browser when using the Grafana dashboards to monitor your application server(s).
InfluxDB is the data source.
Setting up your dashboards in Grafana
Before you can monitor the performance statistics of your application server(s), you must set up your dashboards in Grafana.
InfluxDB must be installed prior to setting up your NexJ CRM dashboards in Grafana. InfluxDB works with Grafana to present performance statistics in easy-to-interpret formats such as graphs and gauges.
To set up your dashboards in Grafana:
Download and install Grafana from the Grafana Labs website. Installation instructions can be found at https://grafana.com/docs/installation/.
Download and install the grafana-diagram panel plugin from the Grafana website.
Configure a data source in Grafana (see Grafana's Getting started for guidance) with the name InfluxDB , and point it to the InfluxDB database specified in the
monitor:influxdb:HTTPSenderchannel connection. Be sure to configure persistent statistics for storage in InfluxDB. For more information, see Persisting statistics to InfluxDB. If you want to configure persistent statistics to StatDatabase as well as InfluxDB, see Persisting statistics to StatDatabase and InfluxDB.In the NexJ System Admin console, open the System page and in the Diagnostics area, click the Download Dashboards button.
Unzip the
GrafanaDashboards.zipfile.From your installation of Grafana, click the
 button (left side navigation), and select Import. Click the Upload .json file button and follow the prompts. Repeat for each dashboard you want to import.
button (left side navigation), and select Import. Click the Upload .json file button and follow the prompts. Repeat for each dashboard you want to import.
Working with dashboards and panels
The Grafana dashboards are designed to assist in monitoring your system's health. They are a set of one or more panels organized and arranged into one or more rows. The dashboards visually summarize your application servers' statistics. Panels with the 
NexJ Model Server dashboard serves as a template with sample dashboards and panels. You can:
Add or subtract dashboards
Set thresholds
Filter by node for details and diagnose any anomalies
Navigate between dashboards by clicking the 
The panels on a Grafana dashboard can be dragged, dropped, and rearranged. They can also be resized. The information displayed in the panels can take the form of graphs, gauges, dashlists, tables, or text. All dashboards use NexJ's persistent stats.
The blue lines on the left side of a panel represent the data over the time interval selected in the top right corner.
The thresholds displayed in the panels are hard-coded. The threshold provides a visual signal that the value might be indicative of a problem. When your servers are working optimally, the gauges on the panels should appear in the green zone. If a gauge shows as in the orange zone, you need to investigate. If usage is in the red zone, there is a problem requiring immediate attention. There are some cases where the thresholds may not be applicable. For example, there is no issue with a low processing rate for a queue if there are no messages to process.
To modify your thresholds:
Hover over the panel name, click the down arrow button
 , and select Edit.
, and select Edit.In the left navigation, click the Visualization button
 .
.Customize your threshold values.
While you can modify the threshold values, they will not be saved when moving to a future release.
Monitoring the Java Virtual Machine
To better monitor details of CPU usage and memory usage, you can filter Java Virtual Machine (JVM) activity by server node. Choose to view all nodes or a specific node from the Node dropdown located at the top left of the dashboard. You can define the time period for the dashboard in the Dashboard time picker located in the upper right of the dashboard. The ability to specify nodes and timeframe is helpful for diagnosing issues as it can help isolate the time and node of the occurrence.
For JVM, the percentage of CPU usage and percentage of memory usage are displayed as gauges.
CPU usage and Memory usage gauges on the JVM dashboard

CPU usage and Memory usage gauges on the JVM dashboard
Click on the CPU usage (%) panel to view the JVM Details dashboard.
There are four graphs displayed:
CPU usage (%)
Memory usage (%)
Garbage collection time (derivative). The amount of time it takes to deallocate memory used by an unreferenced object.
Live thread count. The current number of live/active threads including both daemon and non-daemon threads.
All of these graphs are related, each illustrating a different statistic occurring during the same time period.
Hover over the graph to reveal the usage as a specific percentage for each node on a particular time and date. For example, CPU usage (%) for node 1 might be 2%, memory usage might be 34%, garbage collection time (ms) 90, and live thread count 71.65. All of these numbers are maximums of the mean values.
JVM Details dashboard
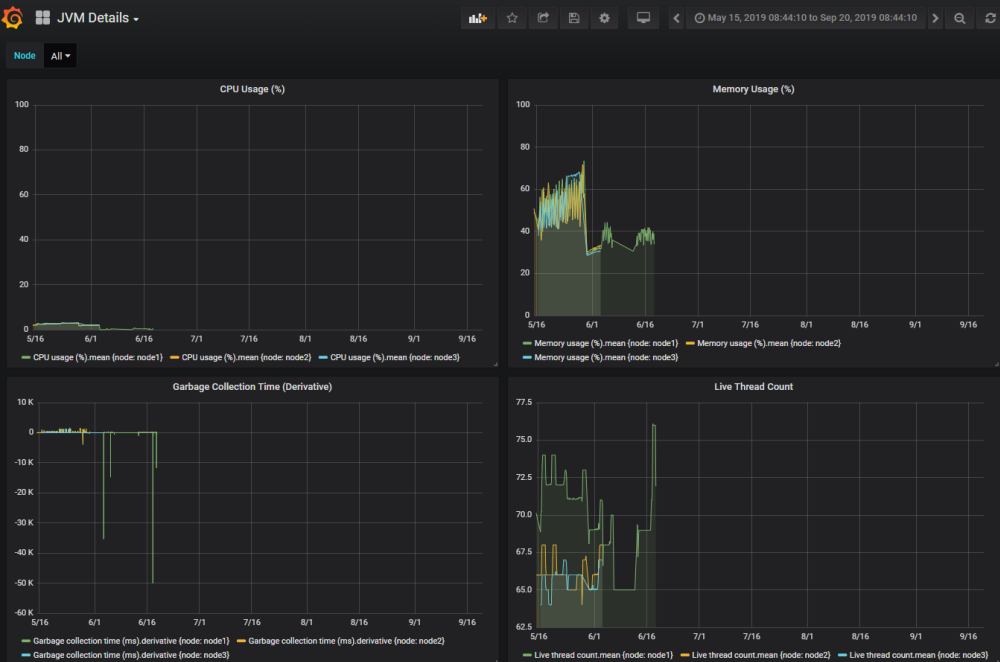
JVM Details dashboard
Sessions
Monitor your HTTP session activity with the four sessions panels. Each uses a gauge as its visualization tool:
Processing time (ms) - the time spent by the application to process a request.
Session activation rate - the rate at which sessions were restored from the persistent store.
Concurrent request count - the number of HTTP requests processed simultaneously.
Session count - the total number of session in memory.
Filter statistics by node for details and to help diagnose any issues. Choose to view all nodes or a specific node from the Node drop-down located at the top left of the dashboard. You can define the time period for the dashboard in the Dashboard time picker located in the upper right of the dashboard. Hover over the
Processing time (ms)
Session count
Session activation rate
Load balancing redirection rate
Concurrent request count
Again, you can narrow down the nodes and date for the information shown on the graphs to help diagnose any issues.
Database
The NexJ Model Server dashboard has the following Database panels in gauge format:
Processing time (ms) - the time taken by this database to respond to each request.
Connection availability (%) - fraction of successful attempts to obtain a connection from the pool.
Connection pool busy wait time (ms) - the time during which a thread waits for a pooled connection to become available.
The Connection availability percentage is the minimum of the means.
Hover over the
Active connection count
Processing time (ms)
Connection availability (%)
Connection pool busy wait time (ms)
To narrow down the detailed statistics and help diagnose any issues, you can filter by data source as well as by node. Select All data sources, or select specific data sources from the Data source drop-down menu located at the top left of the dashboard. Choose to view all nodes or a specific node from the Node drop-down located at the top left of the dashboard. You can define the time period for the dashboard in the Dashboard time picker located in the upper right of the dashboard.
Pools
Use the Pools dashboard to monitor your pool connections for connection issues. For example, a long-running pool connection with a wait time for connections would be indicated on a graph by a non-zero wait time. All percentages presented in the pools statistics are the minimum of the means.
There may be more than one average data point within a time range grouping, as dashboards sample periods are typically one minute. The lowest value of these average data points is the minimum of the means.
The following gauges indicate:
HTTP connection availability (%) - Successful attempts to obtain a connection from the HTTP pool.
TCP connection availability (%) - Successful attempts to obtain a connection from the TCP pool.
UDP connection availability (%) - Successful attempts to obtain a connection from the UDP pool.
Mail connection availability (%) - Successful attempts to obtain a connection with the mail server.
Message queue connection availability (%) - Successful attempts to obtain a connection from the message queue (JMS) pool.
To view the Pool Details dashboard, hover over the
Connection availability (%)
Connection pool busy wait time (ms)
Active connection count
Connection active time (ms)
In the details, you can drill down by channel and node. Select All nodes, or select specific nodes from the Node drop-down menu located at the top left of the dashboard. Choose to view All channels or a specific channel from the Channel drop-down (also located at the top left of the dashboard). You can define the time period for the dashboard in the Dashboard time picker located in the upper right of the dashboard.
Cluster communication
A cluster is a set of nodes that communicate with each other and work toward a common goal. Heartbeats are used by the nodes to monitor each node's status and communicate messages necessary for maintaining operation of the cluster.
The Cluster communication panel is a single graph panel monitoring if heartbeats are being received, or if any are being missed which could indicate networking issues. The nodes receive heartbeats from one another in order to establish their availability.
You can define the time period in the Dashboard time picker located in the upper right of the dashboard. The heartbeats received are equal to the number of nodes multiplied by 20.
Exchange sync
Prerequisites:
Microsoft Exchange Server must be deployed
NexJ Model Server must be configured to sync with Microsoft Exchange Server. For more information, see Microsoft Exchange Server synchronization.
NexJ Enterprise Synchronization for Microsoft Exchange enables the integration of schedule items, tasks, and contacts for different users between NexJ CRM and Microsoft Exchange Server.
On the NexJ Model Server dashboard, the Exchange sync panels (gauges) monitor:
Outbound time to sync (ms)
Successful synchronization (%)
These panels can help with troubleshooting any synchronization-related performance issues, and validate the integrity of the process.
Outbound time to sync is the average amount of time, in milliseconds, it takes for an item such as a contact, schedule item or task created in NexJ CRM, to display in Microsoft Outlook. Synchronization is successful when contacts, schedule items or tasks created in NexJ CRM align with the items in Microsoft Outlook.
Click Outbound time to sync to view the Exchange Push Overview dashboard. From this dashboard, there are several panels where you can obtain more detailed information. You can narrow down the details by selecting the Node , Server and Class from the drop-down menus located in the upper left of the dashboard.
As shown in the following table, some of the panels in the Exchange Push Overview dashboard have additional dashboards, allowing you to dig further into the details for that particular panel.
Panels | Dashboard | Description | Filter by | Panels |
|---|---|---|---|---|
| Exchange Link Health |
|
| |
Inbound Exchange Synchronization | Inbound synchronization refers to the process in which data is received by NexJ CRM from Microsoft Exchange. For example, inbound synchronization occurs when a meeting is created in Microsoft Outlook and consequently a schedule item is created in NexJ CRM. |
|
| |
Outbound Exchange Synchronization | Outbound synchronization is the process in which data is sent by NexJ CRM to Microsoft Exchange. For example, outbound synchronization occurs when a schedule item is created in NexJ CRM and consequently a meeting is created in Microsoft Outlook. |
|
|
Object queues
Object queues are a concurrency control mechanism which supports sending and receiving internal messages between application components. The NexJ Model Server dashboard contains the following Object Queues panels:
Receive rate (m/s) - receive rate of persistent messages for all queues and nodes, as well as transient messages.
Depth - count of persistent messages that await processing from all queues.
Dispatch time - time taken by the dispatcher to prepare the next batch of messages to be processed, and to transition others to their immediate states.
ObjectSystemQueue - number of messages awaiting processing on the ObjectSystemQueue.
To view additional performance information about Object Queues, hover over the 
Health
Receive rate (m/s) - receive rate of transient and persistent messages for all queues and nodes. This is the same as the panel on the NexJ Model Server dashboard.
Dispatch time - time taken by the dispatcher to prepare the next batch of persistent messages to be processed, and to transition others to their immediate states. This is the same as the panel on the NexJ Model Server dashboard.
Get time - time to produce a message for processing by the dispatcher. The dispatcher will wait for a message to be sent (for processing) for up to 10 seconds before returning to the client with no message.
ObjectSystemQueue: Depth - count of persistent messages that await processing on the ObjectSystemQueue, in the last time period.
ObjectSystemQueue: Age - average age of messages as they become ready to be processed, in the last time period.
Depth - count of persistent messages that await processing from all queues.
Failed messages - count of failed messages in the last time period.
Total failed messages - count of failed messages since the last restart.
Receiver count - count of concurrently processing messages.
Dispatcher
Dispatch time - time taken by the dispatcher to transition messages and prepare the next deliverable set.
Dispatch message count - mean dispatch message count.
Candidate query time - time to execute the query to retrieve the next batch of persistent messages to process, with preference given to those with the highest priority and earliest delivery time.
Candidate query count - mean candidate query count, which is the number of queries issued by the dispatcher in its attempts to fill the persistent message batch.
Dispatch message time - duration of dispatcher message-transitioning queries.
Persistent message fraction - fraction of persistent to transient messages received.
To get a closer look at Object Queue statistics, from the Overview dashboard, choose Object Queue Details located at the top right corner.
Depth - number of persistent messages that await processing.
Receive rate
Send rate
Age - average age of persistent messages as they are prepared to be processed (in order of send time and priority). This is the approximate time between when messages are sent and received.
Processing time - average time to process a message.
Universal processing time - average time to process a message, considering all processed since the last restart.
Failed message count
Total failed message count
Commit time - time to commit a message after it has processed.
Filter statistics by queue, node, or message type for details and to help diagnose any issues. You can define the time period for the dashboard in the Dashboard time picker located in the upper right of the dashboard.
Related links
Creating links to folders on the Exchange server
Microsoft Exchange Server Synchronization
Deploying Model Server
Monitoring object queues
Monitoring statistics for NexJ applications
Using NexJ CRM system monitoring tools