
Lesson - Service Persistence Mapping
This lesson presents the basic capabilities of the service data source type.
On completing this lesson, participants will:
- Understand the service data source type
- Implement persistence on a new class through the service mapping
Key Concepts
A class’s persistence mapping specifies how its instances will be persisted in a given data source, which represents a physical store such as a database web service, API, or file system. This is where state is Created, Read, Updated and Deleted (CRUD) during an instance's lifetime. Modelling options vary by data source type and are set in the persistence mapping tab of the class editor.
With the service data source type, you write script that responds to CRUD events including 'new(...), 'read(...), 'update(...), and 'delete(...). This script is run during commit. Two common examples are classes persisting with APIs or stored procedures. Relational data sources completely support all of the object lifecycle events and parameters. With service data sources, you can choose which events and features to script. You always specify the persistence mapping but, for example, you may choose to implement read support and not delete support. Additionally, you may decide to only support certain where clause patterns in the read event because that's all you need for your user interface and it's all the underlying API provides.
A good approach to developing service persisted classes, is to:
- Build your class model.
- Determine the object key and attributes to persist.
- Model the use of your class (for example, user interface or integration scenarios).
- Run your application in NexJ Studio to see what queries and events will be triggered.
Implement the script to support these events.
References to "service" in this module don't necessarily mean integration services found in the integration layer. They refer to general components that provide services, which are usually external to your model such as APIs, stored procedures, and Java libraries.
The service persistence adapter runs in the commit context of the unit of work. This means that you must avoid making changes that will need to be committed in any script you write in the adapter events, including creating new instances of objects, updating instances, deleting instances or other transactional work. If you do this, you can get stuck in a loop.
You can also read about the Service Persistence Mapping in the Model Description Language Reference. The following information describes some of the properties of a service persistence mapping.
To get ready to work with these concepts, do the following:
- In the Persistence layer of NexJ Studio, create a data source with a type of "service" and call it "Service" (if it doesn't already exist).
- In the Business Model layer of NexJ Studio, create a class called
training:SPClass. - Open
training:SPClassand on its persistence tab, set the data source property to Service.
Results
You should see the Service Persistence Mapping editor with tabs for Object Keys, Attribute Mappings, Create, Read, Update, Delete, and Sort Keys. Let's discuss some of the properties of a service persistence mapping.
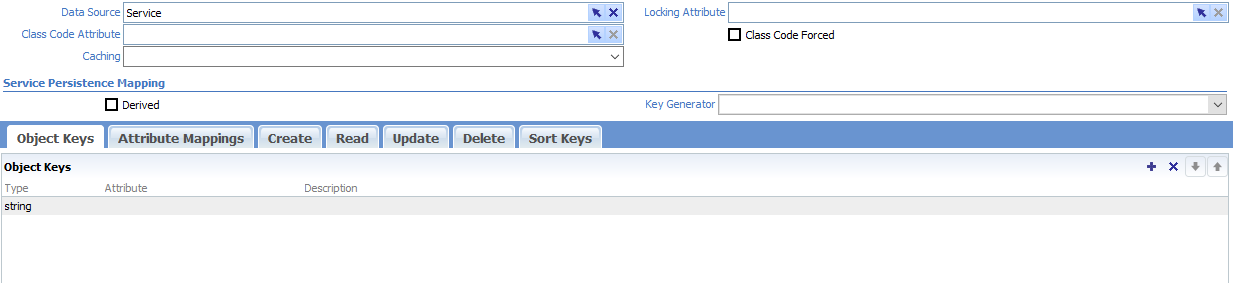
Object Keys
The object key or OID uniquely identifies persisted class instances in memory. It is required for service persisted classes and Its structure is defined by one or more key parts. Each part has a type (string, integer, ...) and an optional class attribute to which the key part is mapped. An attribute can either be mapped as a key part or in the attribute mappings section, not both.
See the Create Mapping and Read Mapping sections for the logic used to set the oid.
Object's OIDs can be accessed using the :oid attribute of an instance, for example, (myPerson':oid) => #<OID:1:V32:00000000000010008000BEEF0000000D>. To create OIDs, you can use the (oid args... function. To access key parts in script, use getValue, for example, ((joe':oid)'getValue 0).
Try it
In the Create tab in the Persistence Mapping of the training:SPClass, enter the following code in the script area:
this
This simple code will return the instance itself, which is essentially equivalent to having some code like (message (: :class "SPClass")). It returns an empty transfer object.
Add a new key part on the Object Keys tab and set its type to binary.
Run the server console and enter the following code:
(training:SPClass'new (: :oid (oid (guid))))
You should see output like the following with the oid set.
; #<Instance<training:SPClass, (oid #z2B4EC2A962144E1081A6C146369AAC90), new>()>
Key Generator
![]()
The key generator automatically creates an object key, if required.
If the :oid attribute is not set through the 'new event, the key generator will generate one and pass it into the create script as the :oid part of the 'this' variable.
KeyGenerator.GUIDGen generates a guid oid if one wasn't already set on the instance and sets (this':oid to #<OID:1:V32:00000000000010008000BEEF0000000D>.
If a key generator is not used, the call to 'new must provide an oid or the create script must set the object key. This can be a script-generated value or perhaps returned from a call to the underlying service, for example, (this':oid (oid (guid))).
Try it.
Set the Key Generator to KeyGenerator.GUIDGen on the Persistence Mapping tab for training:SPClass. Run the server console and enter the following code:
(define i (training:SPClass'new)) (commit) i
Notice the oid is automatically set in the resulting instance.
; #<Instance<training:SPClass, (oid #zAA45851320104E48A26E90F49452CAFA), clean>()>
Derived indicator
Set to true to inherit mapping scripts from the base class; false (default) to ignore the base mappings. Even if this indicator is set to true, the base mappings can be overridden by re-specifying the mapping on the derived class.
Attribute Mappings
Attribute Mappings specify the class's attributes that are persisted for both primitive and association attribute types.
Unmapped attributes are not persisted. An attribute can be mapped as part of the Object Key or the Attribute Mappings, but not both.
Persisted Primitive Attributes
Persisted primitive attributes are set by the underlying service as string, integer, boolean, or any of the other supported primitive types. Their mappings have the following properties:
- Name: The name of the attribute to persist. This must be one of the attributes of this class.
- Max Length: The maximum data length of a string or binary attribute; 0 for unlimited (default).
Persisted Association Attributes
Persisted association attributes are those whose types are another class (for example, +myOwner: Person[0..1]), and are populated by the service with either an oid used to look-up the associated instance(s) or with the full structure of the associated instance(s). There are four main cases:
- Link to the associated class with a foreign key (many-one) or (one-one). Use this attribute's value to link to the associated instance. Configure the mapping's properties as follows:
- Object Source Key property to
false(use this attribute's value, which is the associated instance's oid, to link) - Destination Key property to:
- The primary key index of the associated relationally persisted class
- Or blank for an associated service persisted class (meaning link to the oid of the other class)
- Attributes property empty
- Object Source Key property to
- Link from a foreign key on the associated class (one-many) or (one-one). Use a foreign key on the associated instance(s) to link to this instance. Configure the mapping's properties as follows:
- Object Source Key property to true (use this instance's oid)
- Destination Key property to:
- The appropriate foreign key index of the associated relationally persisted class
- Or the name of the foreign key attribute for an associated service persistence class
- Attributes property empty
:oidof your instance in script, the framework will take care of populating the association attribute with the appropriate instance(s). - Directly instantiate the full associated instance in script. No link required. In this case, the service returns all of the attributes of the associated object(s). These are then used to instantiate the associated objects without a heterogeneous join. Configure the mapping's properties as follows:
- Attributes property to the list of attributes that you will set for the associated object(s)
- The Object Source Key and Destination Key properties aren't used in this case
In your script, set the attribute to the full structure of associated instance(s).
; e.g. for single instance (this'owner (message (: :class "ExternalPerson") (: :oid (oid (myServiceResult'id))) (: firstName (myServiceResult'fn)) (: lastName (myServiceResult'ln)) ) ) ; e.g. for collection (this'owners (collection (message (: :class "ExternalPerson") (: :oid (oid (myServiceResult'primaryId))) (: firstName (myServiceResult'primaryFn)) (: lastName (myServiceResult'primaryLn)) ) (message (: :class "ExternalPerson") (: :oid (oid (myServiceResult'secondaryId))) (: firstName (myServiceResult'secondaryFn)) (: lastName (myServiceResult'secondaryLn)) ) ) )
- Directly instantiate the full or partial associated instance in script but additionally support CRUD operations on the associated class.The service returns some of the attributes of the associated object(s), but CRUD operations on these objects, such as lazy reads of other attributes, deletes, and/or updates, will be handled by the associated class's mapping. Configure the mapping's properties as follows:
- Object Source Key and Destination Key properties are set as in case 1 and 2
- Attributes property is set as in case 3
- Persistence mapping is also configured on the associated class
Person. The account web service returns all of the account's information along with the unique identifier, first name, and last name of the owner. This is specified in the persistence mapping of the owner attribute as;Object Source Key = false, Destination Key = Person.Person_PK, Attributes = "id firstName lastName". If we then do something like((myAccount'owner)'title "Mr.")and commit the change, the read or update events would be invoked on thePersonclass because we are dealing with aPersonattribute not mapped on the Account.
Association Attribute mappings have the following properties:
Name: The name of the persistent attribute. This must be one of the attributes of this class.
Object Source Key: True to use the oid of this class as the source key; False to use this attribute's value as a foreign key to the associated class. Object Source Key and Destination Key are only needed for association attributes that are retrieved with heterogeneous joins. They aren't needed if all attributes are provided by this object's read - in that case, use the Attributes property.
Destination Key: The name of the destination key on the associated class. If the destination class is service persisted, then the destination key may be one of the following:
- The name of an association attribute on the destination class. The association attribute on the destination class will store an OID
- The name of a primitive attribute on the destination class. The mapping scripts will manipulate the attribute as a primitive, but the framework will always wrap that attribute up into a single-part OID.
- The names of more than one primitive attribute on the destination class, whitespace-separated. The mapping scripts will manipulate the attributes as primitives, but the framework will wrap the attributes up as a multi-part OID.
- Unspecified. The destinationKey is the object key (oid) of the association destination class.
If the destination class has Relational Persistence then the destination key is an index specified on the primary table or unspecified for the object key.
Attributes: Used only for association attributes that can be read without performing a separate heterogeneous query on the associated class. Enter the list of attributes from the associated class that will be populated during the read of this class. If all of the associated class's attributes will be set during this class' read event, then Object Source Key and Destination Key are not required. If there are additional attributes on the associated class that aren't specified here and those attribute values are requested, a lazy read will be invoked on the associated class's own persistence mapping.
Create Mapping
The create mapping provides support for creating new instances with your service.
This script executes when the create mapping is triggered by the class's create event. Create will typically be called on (commit) after the 'new event has been called.
; create a new Person in memory (Person'new (: firstName "Joe") (: lastName "Test")) ; #<Instance<Person, null, NEW>(firstName="Joe", lastName="Test")> ; commit will call the Create mapping on the class ; with "this" set to the instance. (commit)
Two special variables are available in the create mapping script - this and properties.
this is a transfer object, or is a collection of transfer objects if the batch property is set to true which indicates support for batch creates. The transfer objects represent the uncommitted instances that will be created. They have the following special attributes:
:class: The string name of the class on which'newwas invoked. This may be a subclass of this class.:event: "create":oid: The OID of the instance being created if a key generator is being used. Otherwise, this OID will be () and it is the responsibility of this script (or the external system) to generate the OID. The generated OID will be communicated back to the framework by setting:oid. The oid must be set to an actual oid - use the(oidfunction to create one. The oid may also be set from the mapped attribute specified in the mapping's object key property. See the "create mapping object key logic" diagram for details.- one value for every primitive attribute on the class with an attribute mapping. Non-primitive attributes are set only if the attribute stores the association's foreign key. In this case, the value will be the OID of the associated instance.
The logic used to set the object key during a call to the create event is as follows.
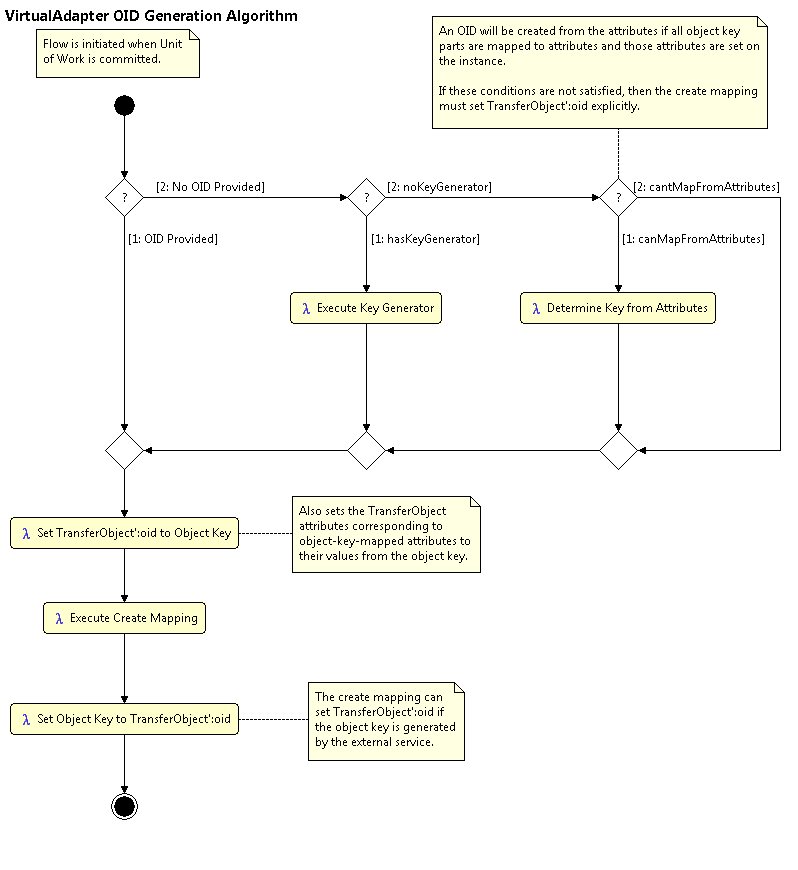
Create mapping object key logic.
properties is an instance of PropertyHolder that contains the properties from the .connections file for the current fragment.
The values returned in the transfer object from the create mapping script is ignored except for the :oid and locking attribute.
If the :oid is not (), then the instance OID will be set to that value. if the class has a locking attribute and it is returned in the transfer object, then the locking attribute value on the instance will be set to that value.
Read Mapping
The read mapping provides support for reading from your service, or services, based on an object query. An object query consists of an attributes list, where clause, orderBy, count, offset and xlock flag.
The read mapping has a set of one or more read cases. You specify a read case for each where clause pattern you need to handle. For example, you may expect queries against a class's unique id (for example, (= (@) 12345), perhaps against primitive attributes (for example, (= lastName "Jones"), complex conditions (for example, (and (= lastName "Jones") (like? firstName "S*"))), or associations (for example, (any? (address city) "Toronto")). Each read case has a where clause pattern, a list of variables, and two scripts (a read script and an optional close script). The adapter runs the script of the first read case that matches an object query's where clause.
Where Clause Pattern: Is a template where expression; blank matches any where clause, () matches an empty where clause. For more information on where clause matching, see the documentation for expr-case and expr-match with special attention to the "?", "or", and "subclass" operators.
(define where `(= (@@ Person addrs) ,(oid #zB4B47BCACA0142A3A65A6EC355758131))) (expr-case where ((= (@@ ,(subclass Entity) addrs) ,entityOid) (logger'debug "oid = " entityOid)) (else (error "err.app.demo.invalidWhere")) )
Variables: Script variables, shared between the read and close scripts.
Read Script: This script executes when the associated where clause pattern is matched.
Variables named after the tokens in the where clause pattern are available in this script. For example, if your pattern it (= (@) ,myId) then a variable myId is available in your script and will be populated with the value from the object query. The following variables are also available:
- class: The class on which the read was executed.
- attributes: The read clause attributes list, after dependencies have been resolved, and security clauses, locking attributes, and type code attributes have been added.
- where: The
whereclause that matched thewhereclause pattern. This where clause is the normalized where clause that is generated by the framework, and will likely differ from the where argument toObject'read. - orderBy: The order by expression.
- count: See
Object'read. - offset: See
Object'read. - xlock: See
Object'read. - associations: List of attributes being read homogeneously. It is a subset of "attributes".
- properties: An instance of
PropertyHolderthat contains the properties from the .connections file for the current fragment.
This script must return a transfer object or collection of transfer objects that contain the data for the instances that were read. To return multiple transfer objects, this script may return a collection, a list, an iterator, or a generator function (see Cursor reads below). Returning () means that no instances were read. You may use (message... function to create a transfer object.
The transfer objects must have a value for every primitive attribute in the list of attributes requested (using the attributes variable). Association attributes are returned as either an OID if it is just a reference, or a transfer object (or collection of transfer objects).
The following special attributes must be set on the transfer objects:
- :
oid: Set to the OID of the instance read. :class: Set to the name of the class of the instance read. This can be(class'name), or it can be the name of one of the derived classes of this class.
If an orderBy expression is specified, (sort-by orderBy) may be used to construct a comparison function then a sorting function like (sort! seq less?) may be used to do the sorting on the collection before you return it.
; order by lastname descending then firstname ascending
(define (sort-by '((lastname . #f) (firstname . #t))))
; note that we leave out the :class and :oid here for simplicity
(define returnCol
(collection
(message (: firstname "Joe") (: initials "M") (: lastname "Test"))
(message (: firstname "Jane") (: lastname "Test"))
)
)
(sort! returnCol sortFunction)
Cursor reads - advanced topic
Cursor reads are supported by the Service Persistence Adapter. They are usually initiated by the (for-each-page... function or with the Object'openCursor event. If you don't do anything special these functions will return the collection returned by the read mapping one record at a time, or by page, until "next" hits the end of the list. This doesn't give you much benefit, because you loaded the entire collection into memory which won't work for very large volumes. That said, if your service does provide cursor (or paging) capabilities, you can expose these capabilities with a yield function.
If your read script returns a yield function (see example below) that wraps up a generator function (in other words, one that gets a new set of data with each call, like a cursor) you can maintain your cursor with state to efficiently move pages of data from storage into memory thus providing improved scalability. The yield function remembers from what point in the generator it was invoked, and the next time the generator is invoked it continues execution on the statement after yield.
The following example shows how to use an external data source that provides a cursor.
; "connection" and "resultCursor" are declared in the "varables" property
; cursor'getNext returns a property formatted collection of transfer objects.
(set! connection (open-connection)) ; open our connection
(set! resultCursor (connection'getResults ...some query...)) ; return:
(lambda (yield)
(let nextResult
()
(define result (resultCursor'getNext)) ; get next record or page
(unless (null? result) (yield result) (nextResult)) ; iterate until done
)
)
Close Script:
The script to execute when a cursor over the read mapping is closed. The return value is ignored. In the preceeding example, the close script would execute (resultCursor'close) and (connection'close).
Update Mapping
The update mapping is called, as you would expect, when updates are made to an instance.
The update mapping has a set of one or more update cases. You specify an update case for each set of updated attributes you want to handle. Each update case has an attributes pattern, a batch indicator, a dirty indicator, a full indicator and and a script. The adapter runs the script of the first attributes pattern that contains all of the attributes to match.
Attributes pattern:
The attributes handled by this update case.
Batch indicator:
True if the mapping supports batch updates. If true, then "this" will be a collection of update transfer objects. If false, then "this" will be a single update transfer object.
Dirty indicator:
Put only changed attributes into "this". If false, a lazy load may be triggered to provide the missing values.
Full:
Put all persistent attributes into "this"; false to put only attributes listed in "attributes".
Script:
This script executes when the associated attributes pattern is matched.
In the script, the following variables are available:
- this: A single transfer object or a collection of transfer objects, depending on the value of the "batch" property.
- properties: An instance of
PropertyHolderthat contains the properties from the.connectionsfile for the current fragment.
On the transfer object, the following special attributes will be set:
:oid: The OID of the instance being updated.:class: The string name of the class of the instance being updated (may be a sub-class of this class.):event: "update"
Additionally, there will be values in the transfer object for the attributes being updated. The attributes that are included in the transfer object are controlled by the dirty and full properties. Non-primitive attributes are set only if the attribute stores the association's foreign key. In this case, the value will be the OID of the associated instance.
The return value of this script is ignored. However, the transfer object will be examined after this script has finished execution.
If the class has a locking attribute, then the locking attribute value will be set. If you invoke your service's update and the locking value has changed, you should throw an exception using (throw-optimistic-lock <transfer-object>).
Delete Mapping
Batch:
True if the mapping supports batch deletes. If true, "this" will be a collection of delete transfer objects. If false, then "this" will be a single delete transfer object.
Script:
The script to execute when this delete mapping is triggered.
In the script, the following variables will be defined:
- this: A single transfer object or a collection of transfer objects, depending on the value of the "batch" property.
- properties: An instance of
PropertyHolderthat contains the properties from the .connections file for the current fragment.
On the transfer object, the following special attributes will be set:
:oid: The OID of the instance being deleted.- :
class: The string name of the class of the instance being deleted (may be a sub-class of this class.) :event: "delete"
If this class has a locking attribute, then there will be one value in the transfer object, containing the locking attribute value.
The return value of this script is ignored.
If there is an optimistic locking error, this script should throw the exception using (throw-optimistic-lock <transfer-object>).
Sort Keys
You can specify a list of sort keys for the class.
Each key has the following properties.
Unique:
True if this sort key is a unique key; false otherwise.
Attributes:
The key attributes, ordered. Use @ for object key; (<name> . #f) for descending sort.
Examples
Getting Started
The following examples aren't complete but are left as an exercise. If you do complete them please message us, and let us know, and we may incorporate your work into this lesson.
For our example service we will use MongoDB (a document oriented database) to persist our data. Download the production release for your operating system from http://www.mongodb.org/downloads. Unzip to any location. Create the database directory in <mongoFolder>\data\db and run mongod.exe from the bin folder.
Download the Java client driver from http://www.mongodb.org/display/DOCS/Java+Language+Center. Reference the driver jar in your project as described in the Scripting with Java lesson by placing the driver jar in the lib folder of your model. Create the lib folder if necessary.
Create a library called mongodb.scm in the Resources/Libraries tab. This library will help with converting between messages (TransferObjects) and mogo BasicDBObjects. Paste the following code into the library.
If you are installing from source, you will need the code from the bson, driver-core, and driver-sync folders. Simply copy the org... or com... subfolders into your projects src folder.
(import
'(
org.bson.types.ObjectId
com.mongodb.ConnectionString
com.mongodb.client.MongoClients
com.mongodb.client.MongoClient
com.mongodb.client.MongoDatabase
com.mongodb.MongoClientSettings
com.mongodb.BasicDBObject
com.mongodb.ServerAddress;
com.mongodb.client.MongoDatabase;
com.mongodb.client.MongoCollection;
org.bson.Document;
java.util.Arrays;
com.mongodb.Block;
com.mongodb.client.MongoCursor;
com.mongodb.client.result.DeleteResult;
com.mongodb.client.result.UpdateResult;
java.util.ArrayList;
java.util.List;
)
)
; com.mongodb.client.model.Filters.*;
; static com.mongodb.client.model.Updates.*;
; Converts a nexj messsage (TransferObject) to a mongodb Document.
; Assumes the message contains either primitives or other transfer objects.
; @arg msg message A message to convert to a BasicDBObject.
; @ret com.mongodb.BasicDBObject A mongo BasicDBObject.
; @example
; (message->dbobject (message (: name "John") (: value "Test")))
; =>#<{ "value" : "Test" , "name" : "John"}>
(define (mongodb:messageToDocument msg)
(when (not (null? (msg':class)))
(msg'class (msg':class))
)
(when (not (null? (msg':oid)))
(msg'_id (oid->string (msg':oid)))
)
(let ((dbObject (org.bson.Document'new)))
(for-each
(lambda (key)
(let ((value (msg key)))
(cond
((message? value)
(dbObject'put key (mongodb:messageToDocument value))
)
(else
(dbObject'put key value)
)
)
)
)
(msg':iterator)
)
;return:
dbObject
)
)
; Converts a mongodb Object to a transfer object.
; Assumes the dbobject contains either primitives or other dbobjects.
; @arg dbobject com.mongodb.BasicDBObject
; @ret message A message containing the fields from the given dbobject.
; @example
(define (mongodb:objectTomessage dbobject)
(let ((msg (message)))
(unless (null? dbobject)
(for-each
(lambda (key)
(msg key (dbobject'get key))
)
((dbobject'keySet)'iterator)
)
)
;return:
msg
)
)
No Associations
Create utility to read from mongo.
No key generation - don't set a key - let it fail. Try to pass a non oid as well. Shouldn't work.
No association - no key generation - set it manually - read it back with utility
No association - key generation - read it back
No association - mongo key - read it back
Association to another service
Do all four examples.
A related subcollection
Do the simple case first - no associations.
In this example, we will add a comments collection to the User class. First, we will create our business model. To start, customize your User class. Select User class - RMB/Customize. Create a new diagram called SPALesson. Show the User class by dragging it from the Business Model/Classes tab to your diagram. Add a class called Comment to your diagram (RMB/New/Class). Add attributes as in the following diagram:

Set the initializers for created to (now) and byUser to ((user)'name). Set the initializers for created to (now)and byUser to ((user)'name). Go to the Comment class's Persistence Mapping tab and select the Service data source in the Data Source field.
Again, the rest is left as an exercise. You might want to try use cases for the following as well. Let us know if you complete some of them so we can incorporate the examples into this lesson.
- An external entity
- External entity with contained subcollection
- External entity with a subcollection
- Implementing a simple read
- Implement read for other attributes
- Implementing update
- Implementing create and delete
- Implementing paged reads (cursors)